

First attempt at a Kaggle competition (Titanic)


I just finnished a course in Machine Learning and Data Science from ZeroToMastery. You might have heard of them before. Highly recommend btw. Anyways, with just listening and coding along with the videos I figured I might evaluate my newly gained knowledge in the subject. I found a machine learning competition at Kaggle (which can be found here: Machine Learning - Titanic) It's a machine learning classification problem to predict which passangers that survived the shipwreck.
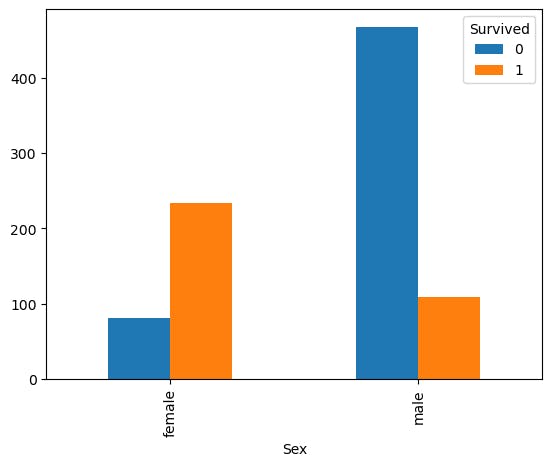
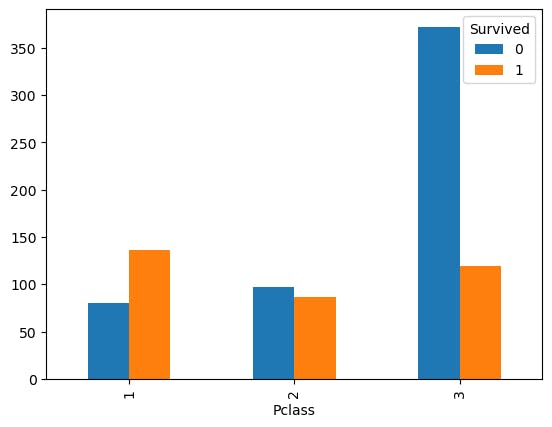
I started of by exploring the training data and figured out that both the Sex and Pclass column had a significant impact to the survival rate based on some of the plots I made. These are just some simple bar charts configured by a crosstab of the columns.
Survival rate of female vs male.
pd.crosstab(df.Sex, df.Survived).plot(kind='bar')
 Survival rate based on which class. 1st to 3rd.
Survival rate based on which class. 1st to 3rd.
pd.crosstab(df.Pclass, df.Survived).plot.bar()
The first time I tried to pre-process the data I only worked on the training data set, this was my first mistake. I should have combined both the training and test data to enable more smooth handling of the non-numerical values as well as for the missing values. I got in trouble later when trying to predict on the test data as there were still missing values in some rows.. Whops.
I re-did all of the pre-processing of the data by making a list of both the training and test data set. This enabled me to loop through both datasets and edit them simultaneously.
For me, the pre-processing of the data is the hardest part. Replacing object and string types to integers and figuring out exactly how it could be implemented is hard. I stumbled across this solution and it helped my quite a bit. I know now that I need more practice with the Pandas Library, but I can definitely see the power of it.
Creating a model and predicting the score was the easiest part for me as this was done several times during the ZTM course. I tried by implementing LinearRegression, KNeighborsClassifier and a RandomForestClassifier. The RandomForestClassifier got the best score on the training data set so I chose to use it for the test data set. Using the .predict() function without any changes to the hyperparameter settings a final accuracy score of 0.74162 was given! This put me in 12.2k place in the competition but I'm so happy anyways! I made it through my first competition and was able to submit my prediction.
The final step now is to tweak the hyperparameters to see if I can get a higher score. Exciting!
I used RandomizedSearchCV with four different hyperparameters for a total of 48 iterations. I chose to change the n_estimators, min_samples_leaf, max_features and bootstrap based basically on random from the documentation. The second submission with these parameters resulted in an accuracy score of 0.75358 which was a slight improvement to the first!
This was my first ever blog post, so be patient with the content. I will improve. =)
Hope you've enjoyed this little draft. Take care.
// Eken